






머릿말
iOS 앱 개발을 할 때에도 “클린 아키텍처” 라는 키워드를 많이 들어왔고, 이게 아키텍처를 짤 때 유의해야하는 것들에 대해 열거한 규칙이 아니라, 특정한 아키텍처 구조를 말한다는 것 까지만 알고있었다. 이번 플러터에 클린 아키텍처를 적용하기 위해서 클린 아키텍처에 대해 2-3일 정도 시간을 투자해 공부를 좀 해봤다. 대략적인 구조는 파악하고 왜 이러한 구조를 선택했는지에 대해서는 이해를 좀 했는데, 아무래도 개념적인 면에서 정보를 습득하다보니 아직 완전히 공감하지는 못하는 포인트가 있었다. 예를 들면 의존성 역전을 넣는 부분 같은 것들! 플러터로 개발을 하면서 이런 부분들을 직접 느껴봐야 할 것 같다.
개인적으로 느낀 점은 MVVM은 뷰를 어떻게 보여주고 관리할 것인가에 대해서 집중한 형태고, 클린 아키텍처는 여기에서 비즈니스 모델 부분을 좀 더 세분화해서 구조를 작성한 것이라고 생각되었다. 찾아보니 이걸 한 번 더 변형하면 헥사고날 아키텍처가 되는 것 같더라.
클린 아키텍처의 지향점?
이걸 먼저 찾아보지 않아서 클린 아키텍처를 이해하는데 시간이 오래 걸렸던 것 같다. ㅜㅜ
클린 아키텍처는 프로젝트를 프론트엔드, 비즈니스 모델, 백엔드 3가지로 나누어 관리하는 방식이다. 핵심이 되는 비즈니스 모델을 유지하면서 프론트엔드 파트를 웹 / 모바일 / PC로 변경하더라도 큰 유지보수 코스트가 들지 않게 확장이 가능하고, 백엔드 파트이 서비스나 프레임워크를 변경하더라도 아무런 문제 없이 서비스가 동작하도록 한다. 레고 부품을 조립하는 것 처럼 비즈니스 모델을 가운데 두고 원하는 백엔드와 프론트엔드를 끼워 사용하는 아키텍처라고 생각하면 이해가 너무 잘된다.
미리 알아볼 걸!!! 클린 아키텍처의 원대한 목표를 미리 찾아볼 걸!!!!!! 흑흑,,, 이걸 알았다면 하루만에 구조를 다 이해하고 받아들였을 것 같다.
전체적인 구조
클린 아키텍처는 각 기능을 크게 3가지 레이어로 나눌 수 있고, 간략하게 다음의 역할을 수행한다.
- Presentation Layer
- 도메인 계층에 이벤트를 전달한다.
- 도메인 계층에서 데이터를 받아와 저장한다.
- 저장한 데이터를 화면에 그려서 보여준다.
- Domain Layer
- 여러 뷰모델에서 사용하는 공통의 코드를 관리한다.
- 뷰모델 범위 이상의 비즈니스 로직을 수행한다.
- Data Layer
- 데이터소스(서버, 로컬DB)에 필요한 데이터를 요청한다.
- 데이터를 받아와 저장공간에 캐싱한다.
- 받아온 데이터를 도메인 레이어에 전달한다.

위 그림에서 볼 수 있듯, 클린 아키텍처는 3개의 레이어로 구성되어 각자의 역할을 수행한다. 앞서 언급한 기능에 따라 데이터의 흐름을 나타내보면, 다음과 같다.
- 특정한 event가 발생하면 Presentation Layer에서 Domain Layer를 호출한다.
- Domain Layer에서는 event에 따라 비즈니스 로직을 실행한다.
- 로직 처리에서 필요한 데이터를 Data Layer에 요청한다.
- Data Layer는 서버, 로컬 DB 등에서 필요한 데이터를 가져와 Domain Layer에게 전달한다.
- Domain Layer는 비즈니스 로직 처리 및 UI를 그릴 수 있게 데이터를 가공해 Presentation Layer에 전달한다.
- Presentation Layer는 받아온 데이터로 화면을 그려 보여준다.
여기에서 특이하다고 느꼈던 점은 의존성의 방향이 데이터 흐름을 따라가지 않고, 중앙을 향해 있다는 점이다. 위 3가지 계층은 바꿔서 이야기하면 프론트엔드, 비즈니스 모델, 백엔드 3가지로 나눌 수 있다. (거의 머리, 가슴, 배) 여기에서 비즈니스모델을 유지하면서 프론트엔드 파트를 앱에서 웹으로, PC로 변경할 수도 있고, DB의 서비스를 교체할 수도 있다. 가장 변경이 될 가능성이 적은 비즈니스모델을 기준으로 의존성을 설계하여 유지보수를 쉽게 만드는 것이 클린 아키텍처의 목표라고 생각한다. 이에 따라 도메인 레이어로 의존성이 향하게 설계되지 않았을까 추측해본다. (아마 맞는 것 같음 :D)
각각의 레이어를 좀 더 들여다보면 아래와 같이 구성되어있다.
Presentation Layer
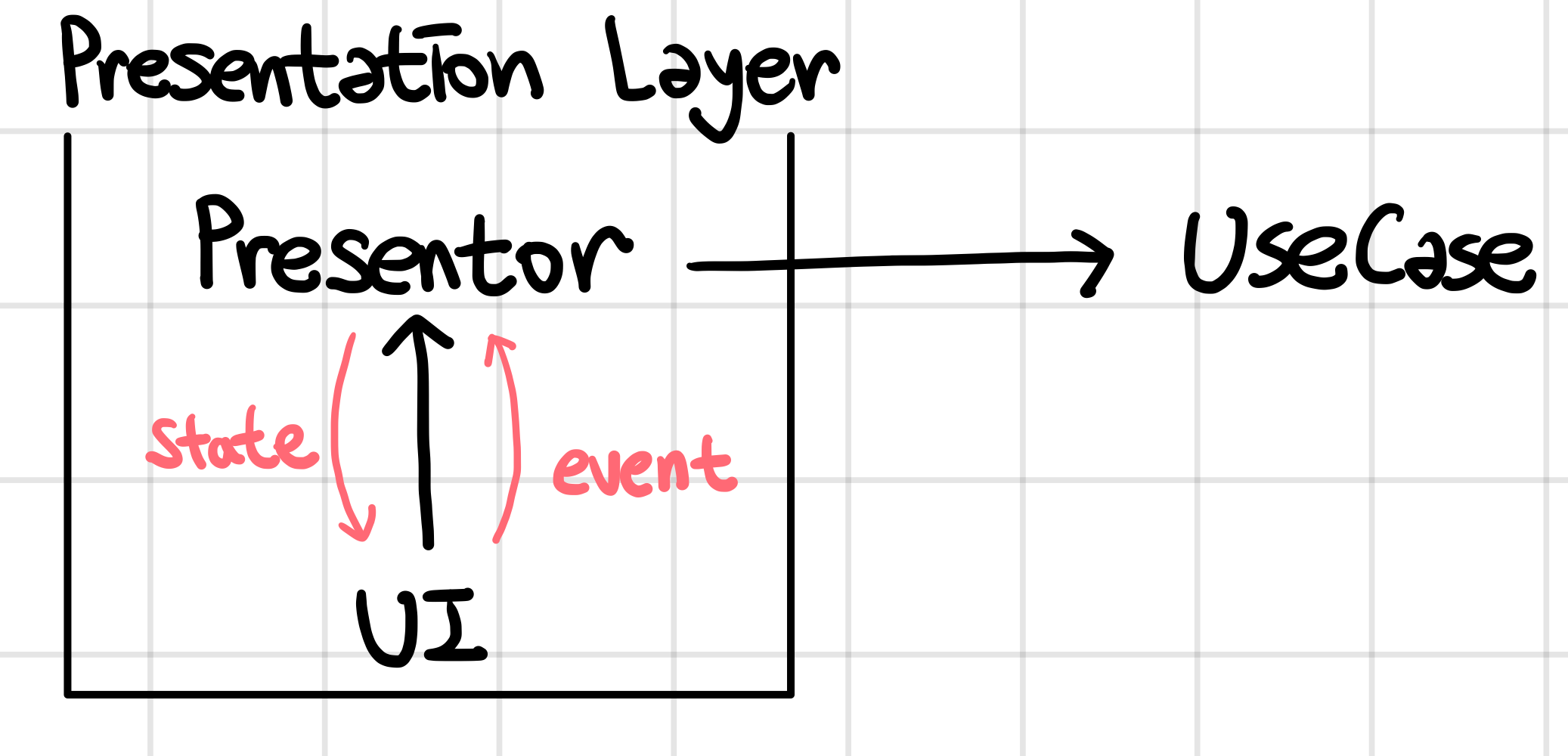
Presentation Layer는 Presentor와 UI를 가지고 있다. 둘의 관계는 MVVM의 ViewModel과 View의 관계라고 생각하면 된다. 따라서, UI는 Presentor에게 일방적으로 의존성을 가지고 있다. 위에서 Presentation Layer의 역할이 다음 3가지라고 소개했었다.
- 도메인 계층에 이벤트를 전달한다.
- 도메인 계층에서 데이터를 받아와 저장한다.
- 저장한 데이터를 화면에 그려서 보여준다.
Presentation Layer 내 컴포넌트들이 각자의 역할을 수행하는 과정을 시나리오와 함께 소개하면 아래처럼 나타낼 수 있다.
- UI는 사용자 이벤트가 발생하면, 이를 Presentor에게 알린다.
- Presentor는 해당 이벤트에 대한 UseCase를 호출해 비즈니스 로직을 시작시킨다.
- UseCase의 결과를 받아와 Presentor의 State에 저장한다.
- UI는 State 값을 observe하고 있다가 변경이 발생하면 위젯을 새로 그린다. (Binding을 통해 알아서 위젯에서 값 가져옴)
Domain Layer
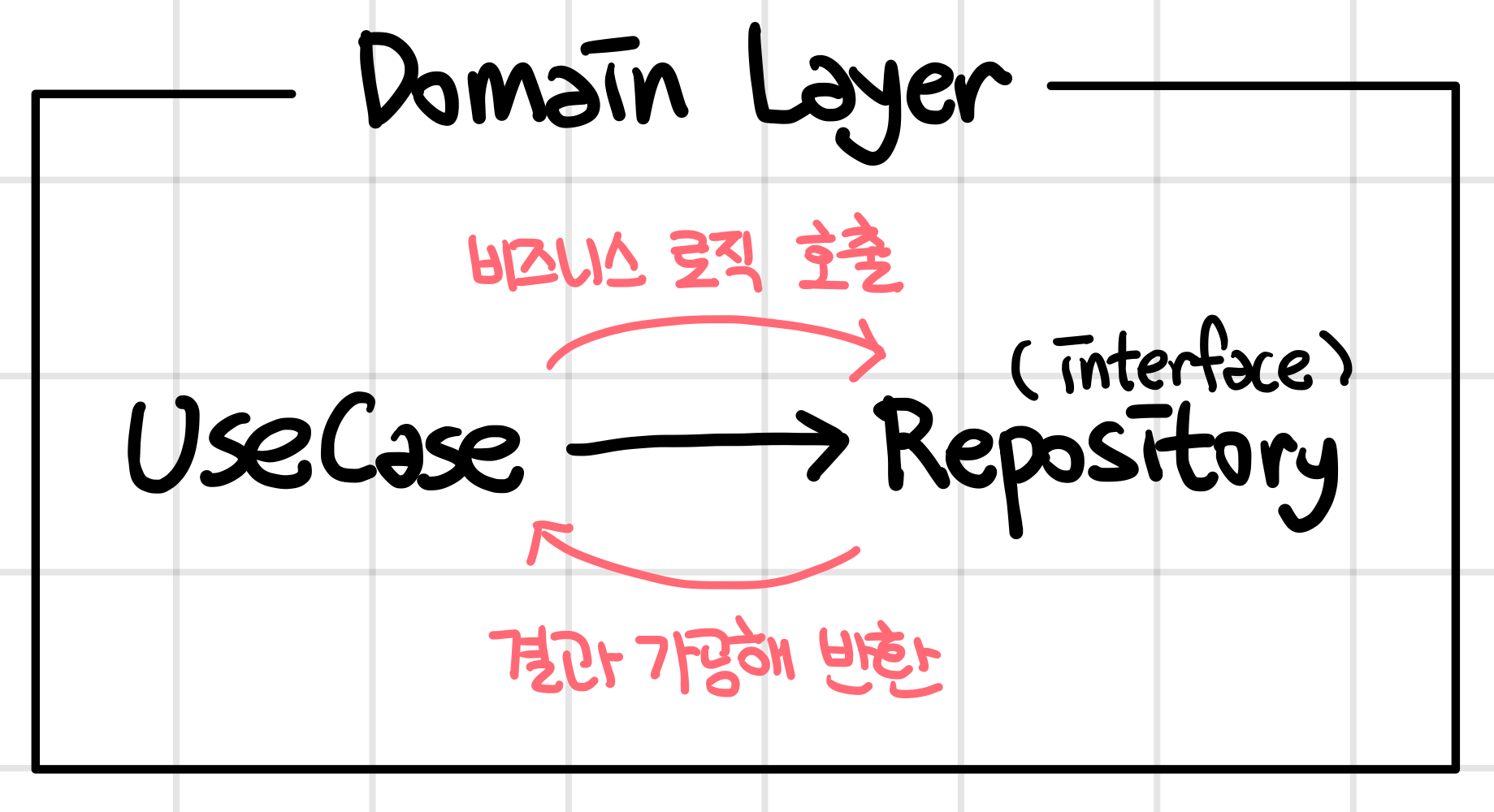
Domain Layer는 UseCase와 Repository를 가지고 있다. Domain Layer의 역할은 아래 2가지이다.
- 여러 뷰모델에서 사용하는 공통의 코드를 관리한다.
- 뷰모델 범위 이상의 비즈니스 로직을 수행한다.
여기에서 UseCase 라는 키워드를 처음 마주해서, UseCase에 대해 좀 더 자세히 찾아봤고, 이걸 ‘사용자가 수행하고자 하는 시나리오’라고 이해하였다. 사용자가 A라는 행동을 하기를 원한다면 Presentor에 의해 호출된 A UseCase가 A 시나리오에 대한 실질적인 비즈니스 로직을 담당하고, 그 결과를 다시 Presentor에게 반환하는 역할을 한다. Repository는 UseCase의 동작을 위해 필요한 데이터들을 가져오는 부분이라고 생각하였다. 하나의 UseCase의 처리를 위해 여러 Repository가 호출되어 실행될 수 있고, 이 실행결과가 합쳐져서 UseCase의 결과가 된다.
Domain Layer의 처리를 예를 들어 설명하면 아래와 같다.
- 사용자가 맛집 리스트를 원한다.
- “맛집 리스트 찾기” 라는 UseCase를 수행한다.
- 맛집 리스트를 찾기 위해 아래 순서로 다양한 레포지토리를 호출해 처리한다.
- Position 레포지토리에서 현재 위치를 받아오는 함수를 호출한다.
- 음식점 DB 레포지토리에서 현재 위치 근처에 있는 맛집 데이터를 받아온다.
- 받아온 맛집 리스트를 사용자에게 보여줄 수 있게 적절히 가공한다.
- 사용자에게 맛집 리스트를 보여준다.
처음에는 여기에서 UseCase가 있는 목적을 이해하지 못했었다. 단순히 ‘Presentor에서 비즈니스 로직을 담당하는 Repository를 직접 호출하면 되지 않나?’ 라고 생각했었다. UseCase와 Repository에 대해 좀 더 찾아보고 내린 나의 결론은 이러하다! 프론트엔드, 비즈니스모델, 백엔드라는 단위로 나누기 위한 구조라는걸 생각하면 바로바로 이해가 되더라.
- Presentation Layer와 Domain Layer는 완전히 분리가 가능해야 한다. (모바일을 웹으로 바꿔도 아무런 문제가 없이 작동해야 함.)
- 근데, Presentor(ViewModel)에서 직접 레포지토리에 접근해서 뭔가 수행하는건 너무 세부적인 내용에 접근하니깐 Presentor에서 Domain Layer로의 의존성이 너무너무 커짐. 이것 때문에 Presentation과 Domain이 얽히게 되면 이후에 프론트엔드를 고치기가 어려워짐. 따라서 추상화가 필요함.
- 어차피 Presentor에서 비즈니스 모델을 호출하는 것은 유저가 원하는 바에 따라 뭔가를 처리하는 경우가 대부분이므로, 이러한 유저의 시나리오 자체를 UseCase라는 하나의 단위로 다루면 관리가 더 편리해진다. (모바일을 웹으로 옮겼을 때 모든 UseCase를 처리하기만 하면 모든 요구사항을 만족하게 된다.)
- 백엔드가 필요 없는 시나리오에 대해서는, UseCase 선에서 처리를 완료할 수 있다. 서버나 로컬DB에서 데이터를 가져와 뭔가 처리해줘야 하는 경우에만 Repository를 호출하면 된다.
여기에서 눈에 불을 켜고 봐야할 지점은 Repository가 interface로 되어있다는 점이다! 이것도 도저히 납득할 수 없는 부분이였는데, Domain Layer가 Data Layer에 의존성을 가지는 것을 막기 위한 “의존성 역전”을 적용한 부분이다. Domain Layer가 Data Layer에 데이터를 요청하고, 이에 대한 반환을 Data Layer가 Domain Layer에게 다시 전달하고 있기는 하지만, Domain Layer가 가지고 있는 인터페이스를 Data Layer가 가져가서 구현하기 때문에, Data Layer → Domain Layer 방향으로 의존성이 발생하게 된다. (오…) Swift로 치면 이게 프로토콜만 선언한 뒤, 해당 프로토콜들의 내부 구현은 신경쓰지 않은 채로 코드를 작성해 UseCase가 정상적으로 작동하도록 만드는 것이다. 여기에 대해서 내가 이해한 바는 아래와 같다.
- 메서드 시그니처와 반환 타입에 대해 고정하는 역할을 담당함. 레포지토리의 디테일한 정보를 은닉할 수 있음.
- 만약 Presentation → Domain → Data 의 방향으로 의존성이 발생했다면, Data → Domain → Presentation 의 순서로 개발이 진행되었어야 한다. 그러나, 인터페이스를 통한 의존성 역전을 적용하면 Presentation → Domain ← Data 가 되어, 핵심적인 개발 파트인 Domain Layer를 우선 개발할 수 있게 된다.
- Domain Layer는 Data Layer의 구현 방식에 상관없이 개발을 진행할 수 있고, Data Layer는 Domain Layer가 가진 인터페이스를 끌어다 Repository를 구현하기만 하면 되기 때문에, 두 계층을 동시에 작업할 수 있다.
- Data Layer가 완전 싹 수정이 된다고 하더라도, Domain Layer는 아무런 신경을 쓰지 않아도 된다! 유지보수 굿!
Data Layer

Data Layer에는 Repository의 구현부와 DataSource가 있다. Data Layer의 역할을 아래 3가지이다.
- 데이터소스(서버, 로컬DB)에 필요한 데이터를 요청한다.
- 데이터를 받아와 저장공간에 캐싱한다.
- 받아온 데이터를 도메인 레이어에 전달한다.
앞서 Domain Layer에서의 Repository의 구현부가 Data Layer에 있다. 즉, Domain Layer에서는 데이터를 어떻게 받아와서 어떻게 가공해 전달하든 신경쓰지 않고, 데이터가 잘 들어오는 것에만 관심을 가지도록 하여, 의존성을 약하게 만들어 백엔드와 비즈니스 로직을 분리할 수 있게 만들었다. API, 로컬 DB, 서버 등 여러 DataSource에서 필요한 데이터를 가져와 가공하는 역할을 Repository가 수행하게 된다.
Data Layer는 이렇게 미리 설계되어있는 인터페이스에 따라 Repository를 구현하여 백엔드 파트를 구현하기만 하면 된다!
각 레이어가 주고 받는 데이터

각 레이어끼리 주고받는 데이터의 형식은 계속 달라진다. 그러나, 이 부분 역시 프론트, 백, 비즈니스를 분리하려는 목적임을 생각하면 간단하게 이해가 된다.
- From Data Layer 데이터를 로컬 DB에서 가져왔을 때, API로 서버에서 받아왔을 때 등 어디에서 어떤 방식으로 데이터를 가져오는지에 따라 데이터의 형태는 계속 바뀌게 된다. 이를 매번 동일한 형식으로 가공하여 Domain Layer에 전달하면, Domain Layer는 언제나 미리 정해진 대로 데이터를 받기 때문에, Data Layer가 어디에서 어떤 방식으로 데이터를 받아왔는지 몰라도 되어 Data Layer로의 의존성이 사라지게 된다.
- To Presentation Layer 지금 Domain Layer를 활용해 구성중인 서비스가 웹인지 모바일인지 PC인지에 상관없이 항상 동일한 형태로 데이터를 넘기고, 플랫폼에 따라 주어진 데이터를 자신에게 적합한 형태로 가공하여 사용하게 된다. 이를 통해 Domain Layer는 현재 어떤 플랫폼에 어떻게 뷰를 보여줘야 할 지에 대해 전혀 고려하지 않아도 되기 때문에 Presentation Layer로의 의존성이 사라지게 된다.
Shout out
SSDC2022
Samsung Software Developer Conference 2022
www.ssdc.kr
김요한 연사자님의 발표를 통해 전체적인 구조에 대해 이해할 수 있었다. 영상으로 발표하신 것도 볼 수 있으니 추천함!
안드로이드 Clean Architecture에 대하여
0. 시작하며 >안드로이드 클린 아키텍쳐에 대하여 객관적으로 알려드리기 위해, [안드로이드 공식 홈페이지의 권장 아키텍쳐]를 토대로 말씀드리고 있음을 밝히며 글을 시작해볼까 해요. 사실
velog.io
위 블로그의 클린 아키텍처 시리즈를 따라 읽으면서 세부적인 내용에 대해 이해할 수 있었다! 추천함.
[Android] 요즘 핫한 Clean Architecture 왜 쓰는 거야? : NHN Cloud Meetup
[Android] 요즘 핫한 Clean Architecture 왜 쓰는 거야?
meetup.nhncloud.com
이걸 읽다가 “A 배달 앱이 너무 잘되니 서비스를 웹으로 확장해 봅시다.” 같은 문장을 보고 클린 아키텍처를 사용하는 목표를 깨달아버렸다!
Architecture & Clean Architecture - part.2
아키텍처와 클린 아키텍처 2
velog.io
여기에서 각 레이어의 역할을 확인할 수 있다!
'Develop > Flutter 개발' 카테고리의 다른 글
| [Flutter] 이펙트 버튼과 Animation Controller (0) | 2023.10.28 |
|---|---|
| [Flutter] Dart는 JIT와 AOT를 한 번에 지원한다고…? (0) | 2023.10.24 |
| [Flutter] 클린 아키텍처스럽게 Riverpod 쓰려는 고민s (2) | 2023.10.15 |
| [Flutter] Riverpod 상태관리 방법 정리 (0) | 2023.10.14 |
| [Flutter] MVC, MVVM (0) | 2023.10.09 |