





프로세스가 무엇이냐
리눅스의 프로세스는 현재 실행중인 프로그램을 말한다. 정확히는 실행중인 프로그램의 인스턴스를 칭하는 말. 프로그램은 단순히 코드와 데이터의 집합이자 파일일 뿐이다. 같은 프로그램이라도 여러 개가 동시에 실행될 수 있고, 이들을 각각 프로세스라고 부른다.
ㅤ
리눅스에서의 프로세스는 다음의 특징을 갖는다.
- 독립적 실행 단위 : 파일이 메모리에 로드되어서 CPU에 의해 실제로 실행되는 동적인 상태
- 고유한 자원 : OS로부터 할당받는 고유한 주소 공간, 스택, 레지스터, 파일 핸들 등의 자원을 가진다. 다른 프로세스는 이 프로세스의 공간을 침범하지 못한다.
- Process ID : 각 프로세스는 시스템 내에서 할당받는 유일하고 고유한 번호를 가진다.
ㅤ
test 라는 실행파일을 백그라운드로 여러 번 실행시켜본 결과. Process ID가 다른 여러 프로세스가 동시에 생성된다.

ㅤ
유의할 점!
PID는 할당할 때 1씩 커지다가, 일반적으로 32768 또는 65536에 도달하면 다시 1부터 할당한다. 1000 이라는 PID를 가지는 프로세스가 소멸되고나면 해당 번호가 다른 Process의 생성 시에 할당될 수 있다. 즉, PID가 완전고유한 자원은 아니다! 따라서, PID 만으로 특정 프로세스가 살았는지 죽었는지를 판단하고, 해당 프로세스와 통신하는 것은 위험하다. (PID만 보고 통신하는 경우, 일부러 특정 프로세스를 죽이고 해당 PID를 바로 발급받아, 뻐꾸기처럼 들어가 앉아서 통신으로 들어오는 데이터를 받아먹을수도 있다)
ㅤ
FreeRTOS의 Task와는 뭐가 다르지?
먼저 Task와 Process의 공통점을 한 번 정리해보자.
- FreeRTOS에서 다루던 Task와는 OS의 실행 단위이라는 것은 동일하다.
- 각자의 실행 Context 를 보유하고 있으며 스케줄러에 의해 CPU 사용 할당을 받는다.
- 스케줄링의 대상이기 때문에, Task와 Process는 상태를 가진다. (아래에서 보겠지만, FreeRTOS의 State Machine과 상당히 유사하다!)
- 유사한 동기화 매커니즘을 사용한다.
ㅤ
그러나, Real-Time 임베디드를 위한 Task와 범용 OS를 위한 Process는 상당한 차이를 가진다.
- Task의 메모리 공간에는 모두가 접근할 수 있었던 것과 달리, Process는 고유의 메모리 공간을 가진다.
- 각각의 Process는 고유의 번호인 PID를 가진다.
- Process는 Text, Data, BSS, Heap, Stack과 더불어 파일 디스크립터(파일, 소켓 등), 환경 변수, 시그널 핸들러, 우선순위와 스케줄링 정보 등을 독립적으로 소유한다.
- Process 끼리는 부모-자식 관계를 형성한다.
ㅤ
프로세스의 상태
FreeRTOS에서의 Task State와 유사하다. 다른점은 MMU(가상 메모리)로 인한 추가적인 상태가 있다는 것.
개념적 프로세스 모델

ㅤ
리눅스의 개념적인 모델에서 프로세스는 5가지의 프로세스 상태 중 하나를 가진다.
- New : 프로세스가 새로 생성됨
- Ready : 모든 준비를 끝마치고 스케줄러에 의해 선택되기만을 기다림
- Running : CPU를 점유하고 실행
- Waiting : 이벤트나 인터럽트를 기다리면서 대기
- Terminated : 처리를 마치고 자원을 해제할 준비
ㅤ
위 그림은 OS에서 사용하는 일반적인 모델의 형태이다. 그래서 내가 다뤄봤던 FreeRTOS와 동일한 구조를 가진다.
ㅤ
실제 리눅스의 프로세스 상태
그런데 실제 리눅스에서는 프로세스가 위 5가지 종류가 아닌 다른 단계를 가진다. 이건 리눅스만의 특징!
ㅤ
RRunning- 현재 CPU에서 실행중이거나 Ready Queue에서 CPU 할당을 대기하는 프로세스
- FreeRTOS의 Ready/Running 상태와 유사
SInterruptible Sleep- 인터럽트(시그널)를 받고 깨어날 수 있는 대기 상태.
- 키보드 입력 대기, 네트워크 수신 대기 등
- FreeRTOS의 Blocked 상태와 가장 유사함
DUninterruptible Sleep- 인터럽트(시그널)를 받아도 깨어나지 않는 대기 상태 (커널 작업의 보호를 위함).
- 디스크 I/O, HW 응답 대기 등 “꼭 필요한 중단”
- 보통 매우 짧은 시간동안만
D상태에 머문다.
TStopped- 프로세스가 실행이 정지된 상태.
SIGSTOP시그널이나 디버거에 의해 중단된 상태. 시그널로 재개 가능하다.
ZZombie- 프로세스가 종료되었는데, 부모 프로세스가 아직 수거해가지 않은 상태.
- 좀비 상태에서 머무는게 정상은 아니다.
Z가 되지 않도록 프로세스 관리를 잘해줘야함.
ㅤ
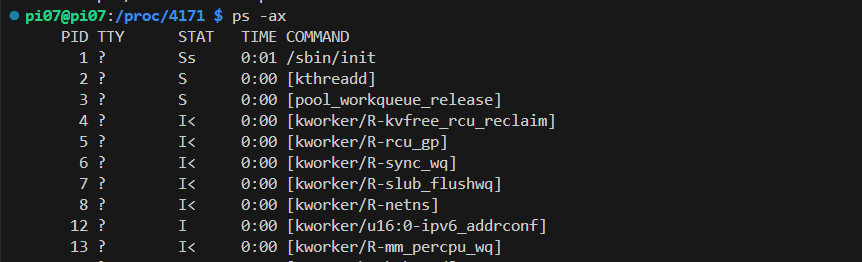
ps 명령어로 프로세스의 정보를 출력할 때, 옵션을 주면 이 STAT 정보를 함께 확인할 수 있다. 기본적으로는 위 State들이 있지만, Linux에서는 추가적으로 보조 플래그와 상태로 프로세스의 상태를 관리한다.
pi07@pi07:/proc/4171 $ ps -ax
PID TTY STAT TIME COMMAND
1 ? Ss 0:01 /sbin/init
2 ? S 0:00 [kthreadd]
3 ? S 0:00 [pool_workqueue_release]
4 ? I< 0:00 [kworker/R-kvfree_rcu_reclaim]
...
680 ? Ss 0:00 /usr/lib/systemd/systemd-logind
759 ? Ssl 0:01 /usr/sbin/NetworkManager --no-daemon
760 ? Ss 0:00 /usr/sbin/wpa_supplicant -u -s -O DIR=/run/wpa_supplicant GROUP=netdev
785 ? Ssl 0:00 /usr/sbin/ModemManager
813 ? S< 0:00 [krfcommd]
...
4170 pts/5 Ss+ 0:00 sudo ./pa 0
4171 pts/5 R< 4:00 ./pa 0
4595 ? S 0:00 sleep 180
4815 ? I 0:00 [kworker/0:2-events]
5033 pts/4 R+ 0:00 ps -axI 상태는 Idle을 의미한다. 가장 아래쪽에 보면 현재 실행중인 프로세스인 R 이 있는 것도 확인할 수 있다.
ㅤ
시그널에 의한 상태 변경
SIGKILL 등을 통한 강제종료 시
- 대기/준비 상태에서 바로 종료 상태로 이동된다.
- 커널이 바로 프로세스에게 할당된 모든 자원을 회수하고 상태를 종료로 변경해버린다. 이때는 프로세스가 실행중이던 내용을 정리할 기회가 없음 (강제종료 같은 느낌인 듯)
ㅤ
SIGTERM 을 통한 종료 요청 시
- 대기/준비 → 준비 → 실행 (시그널 핸들러를 실행함) → 종료
- 이때는 프로세스가 시그널을 확인하고, 핸들러 코드를 실행해주고나서 시스템 호출로 직접 종료를 요청.
- 윈도우에서 종료 시 → 파일 저장할지 물어보는거 가 이 절차에 해당하는 듯.
ㅤ
리눅스의 프로세스 스케줄링 방식
Unix는 기본적으로 시분할 스케줄링 + 우선순위 기반의 선점 방식을 사용한다.
ㅤ
사용자는 각 프로세스에게 Nice 값을 지정해줄 수 있다. 이 Nice 값은 프로세스가 얼마나 “친절한가” 혹은 얼마나 “이기적인가”를 나타내는 값으로, 내가 지정해주는 우선순위라고 보면 된다. Nice 값은 -20 ~ +19 사이에 값을 가지는데, -20이 ‘가장 이기적인 프로세스’이고, +19가 ‘가장 착한 프로세스’이다. 이기적인 프로세스는 CPU를 최대한 점유하려고 하고 (우선순위가 높고) 착한 프로세스는 다른 프로세스에게 작업 시간을 양보한다. FreeRTOS에서의 우선순위가 이 Nice 가 하는 역할이라고 보면 된다.
ㅤ
리눅스 커널은 거기에 더해서, 모든 프로세스에게 완전히 공정하게 CPU 할당 시간을 분배(Completely Fair Scheduler)하는 것을 추구한다.
ㅤ
여기에서 “공정하다”는 것은 높은 우선순위의 프로세스나 낮은 우선순위의 프로세스나 동일하게 CPU를 할당받을 수 있음을 말한다. 특정 프로세스의 우선순위가 낮다고 하더라도 모든 높은 우선순위의 Task가 처리되고 나서야 CPU를 점유할 수 있게 하는게 아니라, 낮은 우선위이더라도 어느정도는 공정하게 CPU를 할당받을 수 있도록 하는 복지제도의 유무에 대해서 말하는 것이다. 또, Block 되느라 CPU를 조금밖에 쓰지 못한 프로세스는 다음번에 더 긴 시간을 할당받음으로서 다른 프로세스들과 동일한 CPU 시간을 제공받는 방식을 사용한다.
낮은 우선순위 프로세스의 CPU 점유 사각지대를 해소하라!
ㅤ
각 프로세스가 얼마나 CPU를 점유할 지는 Nice 값과 실제 프로세스가 실행중에 CPU를 점유한 시간에 따라 결정된다.
- 사용자(개발자)가 프로세스에 Nice 값을 지정해준다.
- 설정해준 Nice 값을 기준으로 커널이 각 프로세스의 Weight를 계산한다. 이때 프로세스의 Weight는 현재 실행중인 모든 프로세스의 Weight 총합에서 자신의 Nice 만큼의 비율을 가져온다.
- Weight로부터 Time Slice를 계산하고, Priority를 계산한다. 시스템 설정에 따른 전체 Time Slice에서 전체 Weight 대비 자신의 Weight 만큼의 Time Slice를 배정받는다.
- 실제 실행에서 CPU를 점유한 시간과 Weight 값을 기반으로 vruntime을 계산한다. $\frac{\text{점유시간}}{Weight}$
- vruntime 값이 가장 작은 프로세스부터 처리해준다.
ㅤ
위 과정을 예시와 함께 한 번 살펴보자!
ㅤ
사용자(개발자)가 설정해준 Nice 값을 기준으로 현재 실행중인 프로세스들간의 Weight 를 계산한다. Nice가 낮을수록 Weight가 커진다!
프로세스 A: Nice = 0 (일반)
프로세스 B: Nice = -5 (높은 우선순위)
프로세스 C: Nice = 10 (낮은 우선순위)
프로세스 A의 Priority : 120 + 0 = 120
프로세스 B의 Priority : 120 + -5 = 115
프로세스 C의 Priority : 120 + 10 = 130
Nice = -5 → Weight = 3121 (B)
Nice = 0 → Weight = 1024 (A)
Nice = 10 → Weight = 335 (C)여기에서 Priority와 Weight는 사실상 같은 정보인데, 표현 방식이 다른 것일 뿐이다. ㄷㅈ
- Priority : 커널이 프로세스를 추적할 때 사용하는 정보
- Weight : CFS 스케줄러가 Time Slice, vruntime을 계산할 때 사용하는 정보
ㅤ
그 다음, 여기에서 각 프로세스 별 Time Slice를 계산한다. Time Slice는 전체 Time Slice를 프로세스끼리 Weight 비율만큼 나눠서 가져간다고 생각하면 된다.
전체 Time Slice = 100ms (시스템 설정)
A의 Time Slice = 100 × (1024 / (3121+1024+335))
= 100 × (1024 / 4480)
= 22.8ms ≈ 23ms
B의 Time Slice = 100 × (3121 / 4480)
= 100 × (0.697)
= 69.7ms ≈ 70ms
C의 Time Slice = 100 × (335 / 4480)
= 100 × (0.075)
= 7.5ms ≈ 8msㅤ
여기까지는 Nice 값에 의해 정적으로 결정되는 영역이다. 리눅스에서는 이렇게 프로세스 설정에 따라서 결정되는 우선순위 말고도 실제 실행 상황에서 각 프로세스가 공정하게 시간을 할당받을 수 있도록 한다.
ㅤ
만약 B, C 프로세스가 중간에 Block 되는 것 없이 모든 Time Slice를 사용했고, A 프로세스가 절반 처리 후 I/O를 기다리며 Block으로 내려갔다고 하자. 그러면 계산되는 각 프로세스의 vruntime은 아래와 같다.
B가 70ms 실행 후:
vruntime_B = 70ms / 3121 = 0.0224
A가 12ms 실행 후:
vruntime_A = 12ms / 1024 = 0.0117
C가 8ms 실행 후:
vruntime_C = 8ms / 335 = 0.0239ㅤ
스케줄러는 이제 위 vruntime 을 보고 다음에 어떤 프로세스를 실행할 지 결정하게 된다. 처음부터 실행한 순서는 그러면 B → A(중간에 Block됨) → C → A(남은 시간 채우러 먼저 올라옴) → B → C → … 이런식으로 진행이 되면서 프로세스간에 공정하게 CPU를 점유한다!
ㅤ
nice가 낮은 프로세스가 더 높은 우선순위를 가지며, nice 값이 낮을수록 CFS 에서 vruntime 값이 더 천천히 올라, 사실상 더 많은 CPU 시간을 받는다. 즉, 더 높은 우선순위 → 더 많은 CPU 시간 → 더 빠른 처리.
ㅤ
어라라? 분명 선점형 스케줄링이라고 했는데, 그러면 Nice 값이 높은 (우선순위가 낮은) 프로세스가 왜 더 먼저 실행되는거지? 라는 생각이 들었다.
그런데 프로세스의 Nice 값과 커널이 생각하는 프로세스의 우선순위는 좀 다르다. 리눅스에서 스케줄링 선점을 위한 프로세스의 우선순위는 동적으로 변한다. “선점”의 기준이vruntime이 되기 때문. 다음 실행할 프로세스를 선택할 때 (하나의 프로세스가 끝났다거나 / Block 되어서 다른 프로세스를 실행해야 한다거나 / Block에서 깨어나서 뺏어올지 결정해야 한다거나)vruntime값을 보고 선택하기 때문에, 사실상 이 값이 동적 우선순위가 된다.
ㅤ
이외에도 실시간 프로세스 (Real-Time Process) 도 지원한다. Nice를 따지는 일반 프로세스보다 우선순위를 항상 높게 가져서 항상 먼저 처리될 수 있도록 한다.
ㅤ
프로세스 관리 방법
프로세스 제어 블럭 (PCB - Process Control Block)
FreeRTOS에서 Task에 대한 정보를 담았던 구조가 TCB였던 것처럼, 리눅스에서는 프로세스의 정보를 담기 위해서 PCB를 사용한다. 여기에서는 커널의 프로세스 스케줄링을 위한 정보 + 프로세스 실행 시 필요한 정보 + 프로세스 메타정보 등을 모두 담고있다. 전체 구조체에 대한 코드는 여기에서 확인할 수 있다.
ㅤ
struct task_struct {
// 프로세스 식별
pid_t pid; // 프로세스 ID
// 스케줄링 관련
int prio; // Priority (0-139)
int static_prio; // Nice로부터 계산된 정적 우선순위
int normal_prio; // 조정된 우선순위
// CFS 스케줄링 (vruntime 등)
u64 vruntime; // Virtual Runtime
// 프로세스 상태
volatile long state; // 현재 상태 (TASK_RUNNING, TASK_INTERRUPTIBLE 등)
// 메모리 정보
struct mm_struct *mm; // 프로세스의 메모리 정보 (페이지 테이블 등)
// CPU 실행 컨텍스트
struct thread_struct thread; // CPU 레지스터, SP, PC 등
// 부모 자식 관계
struct task_struct *parent;
struct list_head children;
// 다른 많은 정보들...
};ㅤ
이 구조체에 담긴 정보들은 커널이 내부적으로 관리하기 때문에 내가 확인해보지는 못하지만, 비슷하게 프로세스의 정보들을 모아둔 파일은 /proc/P_ID/status 파일에서 확인해볼 수 있다. 여기에서도 다양한 정보들을 보여준다.
ㅤ
여기에서, CPU 실행 Context를 담는 thread_struct는 이렇게 구성된다. 만약 프로세스가 실행되다가, Time-Slice 후 다른 프로세스에게 선점된다면 thread 구조체에 현재 CPU 상태를 저장하고 → 이후 복원될 때 이 구조체에서 값을 가져오게 된다. 전체 구조체에 대한 코드는 여기에서 확인할 수 있다.
struct thread_struct {
unsigned long sp; // Stack Pointer (SP 레지스터)
unsigned long pc; // Program Counter (PC 레지스터)
unsigned long fp; // Frame Pointer (FP 레지스터)
// 다른 레지스터들...
unsigned long fpu_state; // FPU(부동소수점) 상태
};ㅤ
메모리 정보를 담은 mm_struct 에는 가상 메모리를 가리키는 주소들이 들어있다. 여기에는 프로세스를 실행시킬 때 메모리에 할당되는 구역들에 대한 정보들이 담겨있다. 전체 구조체에 대한 코드는 여기에서 확인할 수 있다.
struct mm_struct {
struct vm_area_struct *mmap; // VMA 리스트 (가상 메모리 영역들)
unsigned long start_code; // Code 영역 시작
unsigned long end_code; // Code 영역 끝
unsigned long start_data; // Data 영역 시작
unsigned long end_data; // Data 영역 끝
unsigned long start_brk; // Heap 시작
unsigned long brk; // Heap 현재 위치
unsigned long start_stack; // Stack 시작
pgd_t *pgd; // Page Global Directory (페이지 테이블)
...
};ㅤ
여기에서 pgd_t 구조체에는 자신이 가지고 있는 전체 메모리에 대한 테이블을 가지고 있고, 이를 참조해서 가상 메모리 주소 → 물리 메모리 주소로 변환한다.
나는 이게 무조건 TLB를 통해서 HW적으로 발생하는 줄 알았는데, TLB는 그냥 캐시일 뿐이였다. (그래서 TLB miss가 발생하는구나, 맞다.) TLB miss가 발생한 시점에 그렇다면 물리 메모리 주소를 어디에서 찾냐? 이 페이지 테이블에서 주소를 찾아주어야 한다. 따라서, 각 프로세스는 전체 페이지 테이블을 메모리에서 관리하고 있어야 한다.
ㅤ

요 가상주소의 느낌을 간단히 그림으로 그려보면, 요렇게 구성된다.
여기에서 Decode를 통한 실제 메모리 영역을 찾아나서는 과정에 대해서는 놀랍게도 7년전의 내가 정리를 해뒀다…! 미친인간. 이걸 어떻게 고작 학부 2학년때 다 공부하고 학점까지 잘 받아냈던거지??? 박성민그는대체누구인가????? 띄어쓰기를하지않는이유는과거의나를향한존경심이여백없이빽빽해서야
ㅤ
가상 주소 → 물리 주소 변환 (간단히)
프로세스간의 Context-Switch가 발생했다고 해보자.
프로세스 A의 가상 주소 0x1000 → 물리 주소 0x5000 으로 매핑이 되어있고, 이 정보가 TLB에 들어있다고 해보자. 프로세스 B로 Context-Switch가 일어나고 나서, B의 가상 주소 0x1000 에 접근하려고 할 때, 단순히 TLB를 바라보면? 0x5000으로 가라고 되어있다. 그런데 이건 A의 물리 주소이기에 B가 함부로 접근할 수 없는 영역이다.
ㅤ
그래서, 프로세스 A → B 로 전환할 때 TLB를 모두 비워준다(TLB Flush). 그 다음, TTBR 레지스터(ARM 기준, Translate Table Base Control Register)에 B의 테이블 주소를 넣어주고, B를 실행시킨다. 그러면 B의 가상 주소에 대해 접근할 때 B의 페이지 테이블을 기준으로 물리 주소로 변환하게 된다.
ㅤ
개어렵네. 그냥 HW가 “딸깍” 해주는 건줄 알았는데, 역시 이것도 마법이 아니라 맨파워였던건가. 필요하다면 나중에 이 과정이 또 아티클로 하나 튀어나올 예정.
ㅤ
프로세스 테이블
프로세스 테이블은 현재 시스템에 존재하는 모든 프로세스에 대한 정보를 관리하는 자료구조이다. OS가 모든 프로세스를 추적하고 제어하는데에 사용한다. 스케줄러도 다음 실행 프로세스 선택에 프로세스 테이블을 이용한다. PID를 기준으로 프로세스는 식별되며, 프로세스의 현재 상태와 스케줄링에 필요한 정보, 자원 사용량 등을 기록한다.
ㅤ
커널이 프로세스를 관리하기 위해서는 2가지 관리에 대한 고려가 필요하다.
- 다음 실행할 Ready 프로세스 스케줄링 (Ready 중
vruntime이 가장 작은 프로세스를 찾아라) - 부모-자식 프로세스 관계 추적 (부모 프로세스가 죽었을 때 → 자식에 대한 처리가 필요하니깐)
ㅤ
우선 스케줄링 관점. 모든 프로세스 사이에서 다음 실행할 프로세스를 찾는 것은 너무나도 복잡하다. 그래서 어떻게 설계했나?
- 일단 후보를 추리기 위해서 각 프로세스 상태별로 그룹을 분리해준다. → Ready 끼리만 모으기 + Sleep 끼리만 모으기 + …
- Ready에서
vruntime을 기준으로 정렬한다. 사실 모든 프로세스를 정렬할 필요 없이, 가장vruntime이 작은 프로세스만 빨리 찾을 수 있으면 된다. 그래서 우선순위 큐를 사용한다. - 그런데 그 내부를 어떻게 구성하냐? 리눅스에서는 효율적으로 탐색 및 삽입이 가능한 레드-블랙 트리 구조로 구현한다.
ㅤ
그렇다면 부모-자식 프로세스는 어떻게 관리하나?
- 자식은 누가 부모인지 가리키기 / 부모는 자식이 누가 있는지 가리키기 만 하면 된다.
- 이미 프로세스의 정보를 관리하는 훌륭한 PCB가 있으니, 여기에다가 부모, 자식을 가리키는 포인터를 넣어준다.
ㅤ
그래서 프로세스 테이블에 대한 간략한 구조는 아래처럼 구성된다.
프로세스 테이블:
├─ Ready Queue (Red-Black Tree 기반 우선순위 큐) - vruntime 작은 순서로 정렬
├─ Sleeping Queue (Linked List 또는 Hash Table) - 순서가 변경되지 않고, 누가 먼저 깨어나는지만 알고있으면 됨
├─ Stopped Queue (Linked List) - 정렬 필요가 없으므로
├─ Running (현재 프로세스)
└─ 각 PCB:
├─ 스케줄링 정보 (vruntime, priority, nice)
├─ CPU 상태 (thread_struct)
├─ 메모리 정보 (mm_struct)
├─ 부모 포인터
└─ 자식 포인터들ㅤ
프로세스 영역 테이블
프로세스 영역 테이블은 프로세스의 가상 메모리 관리와 관련 정보를 담는 자료구조이다. 프로세스가 사용하는 [코드, 데이터, 힙, 스택] 같은 논리적인 영역을 분할하여 관리한다. 아까 앞에서 살펴봤던 mm_struct 가 바로 이 프로세스 영역 테이블이다. 여기에 있는 변수값을 확인하면 각 프로세스의 메모리 공간의 시작과 끝 주소를 빠르게 확인할 수 있다. 다시 한 번, 전체 구조체에 대한 코드는 여기에서 확인할 수 있다.
struct mm_struct {
struct vm_area_struct *mmap; // VMA 리스트 (가상 메모리 영역들)
unsigned long start_code; // Code 영역 시작
unsigned long end_code; // Code 영역 끝
unsigned long start_data; // Data 영역 시작
unsigned long end_data; // Data 영역 끝
unsigned long start_brk; // Heap 시작
unsigned long brk; // Heap 현재 위치
unsigned long start_stack; // Stack 시작
pgd_t *pgd; // Page Global Directory (페이지 테이블)
...
};ㅤ
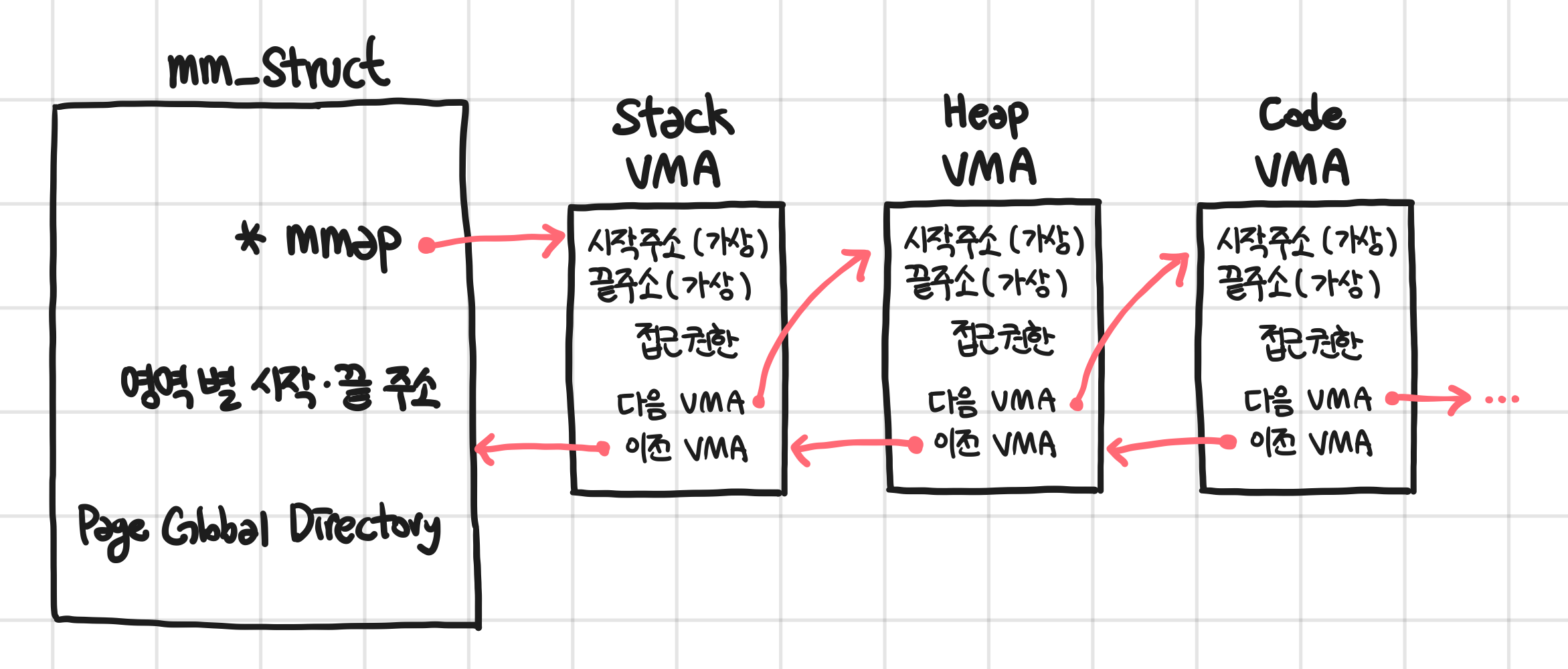
여기에서 VMA 영역 vm_area_struct 가 가지고 있는 정보가 또 재미있다.
struct vm_area_struct {
unsigned long vm_start; // 이 영역의 시작 주소
unsigned long vm_end; // 이 영역의 끝 주소
unsigned long vm_flags; // 권한 (R/W/X, Shared/Private 등)
struct vm_area_struct *vm_next; // 다음 VMA로의 포인터
struct vm_area_struct *vm_prev; // 이전 VMA로의 포인터
// 다른 정보들...
};ㅤ
VMA는 자신이 지정하는 영역과 해당 영역의 가상 메모리의 시작주소, 끝주소, 접근 권한을 가지고 있다. 만약 Stack 위치를 가리킨다면 Stack의 시작주소, 끝주소, 접근 권한(읽고 쓰기 모두 가능)을 가진다. 만약 이 영역이 수정 불가능한 Code 영역이였다면 접근 권한은 읽기만 가지고 있다.
ㅤ
그림으로 본다면 아래 처럼 구성된다!
ㅤ
그런데 여기에서 한 가지 의문이 생겼다. 왜 굳이 이걸 Linked List 형태로 관리하지?
사실 mm_struct 구조체에 Stack의 시작과 끝, Heap의 시작과 끝, Code의 시작과 끝 같은 값들이 이미 변수에 들어있었다. 그럼에도 이걸 왜 굳이 리스트로 한 번 더 관리할까? 라는 의문이 생겨서 찾아봤다. 굳이 구조체 변수로 한 번에 값 접근이 가능한걸 연결리스트로 또 넣어줄 필요가 있을까? 라는 생각. 🤔🤔
ㅤ
그리고 얻게된 정보,리눅스에서는 프로세스에 가상 메모리 영역이 동적으로 붙을 수 있다. 예를 들면, mmap() 시스템 콜을 통해 파일이 메모리에 매핑되는 File-Mapped Memory 같은게 생겼을 때, 이 가상 주소를 가리키기 위해서 VMA 가 필요하다. 이걸 만약 mm_struct에서 변수로만 정보를 저장한다면? 언제 사용될 지 모르는 + 몇 개나 사용될 지 모르는 특정한 메모리 영역을 위해서 mm_struct에 미리 변수를 할당해두는게 오히려 더 손해보는 일이다!

ㅤ
간단하게 살펴본 바이지만, Stack이나 Heap, Data 같은 영역이 파편화되는 상황은 잘 없는 것 같다. 영역들이 각각의 물리적 메모리에 쪼개지기는 해도, 하나의 Stack이 물리적 메모리에 2개로 분리가 되지는 않는다. Maybe 캐시미스 등을 고려한 설계가 아닐까 예상된다. (그치만 진짜 분리 안되는지 + 설계의도 부분은 모두 팩트체크 필요함!!)
ㅤ
또 궁금해졌다. 아니 대체 VMA가 얼마나 생기기에 이렇게 구조까지 만들었나? 라고 생각했는데, 생각보다 VMA가 더 많이 사용되고 있었다. 하나의 프로세스는 평균적으로 20개 정도의 VMA를 가진다. 프로세스의 VMA 개수 확인은 아래쪽 실습에서 다뤄보았다.
[ Text + RO data + RW data + 공유 라이브러리마다 VMA 별도 + 힙 + 스택 + 메모리 맵 파일 + 기타 ]파이어폭스 같은 경우, 많으면 VMA가 천 개 이상 생길수도 있다. (효율을 위해서는 탐색속도가 진짜 중요)
ㅤ
두 용어는 헷갈리니깐
한 번 정리하고 가자.
| 구분 | 프로세스 테이블 (PCB) | 프로세스 영역 테이블 |
|---|---|---|
| 주 관리 대상 | 프로세스 자체의 상태 및 제어 정보 | 프로세스의 메모리 영역 및 속성 정보 |
| 핵심 정보 | PID, 상태, 스케줄링 정보, 부모/자식 관계 | 코드, 힙, 스택 등의 가상 주소, 크기, 접근 권한 |
| 목적 | CPU 스케줄링 및 프로세스 제어 | 메모리 보호 및 주소 변환 |
실제로 까보자!
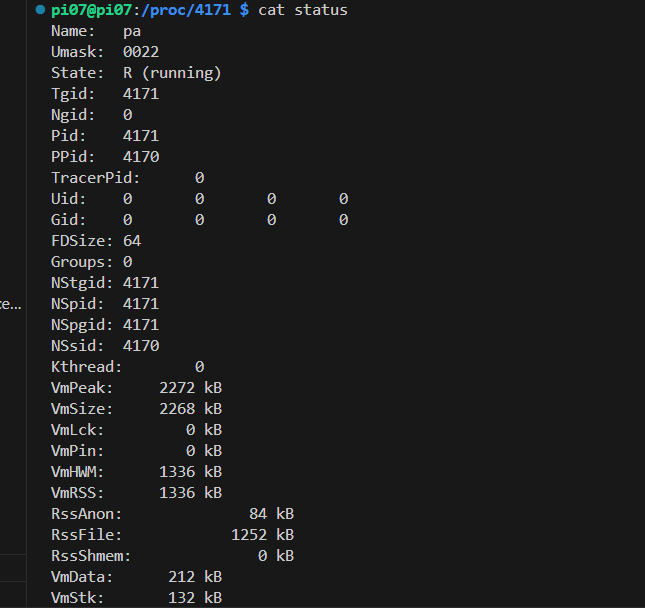
앞서 언급했던 것처럼 /proc/P_ID/status 파일의 내용을 확인해보면, task_struct의 정보 + mm_struct의 정보들을 확인해볼 수 있다. 이 파일에는 특히 정적인 데이터들이 담겨있다.
pi07@pi07:/proc/4171 $ cat status
Name: pa
Umask: 0022
State: R (running)
Tgid: 4171
Ngid: 0
Pid: 4171
PPid: 4170
TracerPid: 0
Uid: 0 0 0 0
Gid: 0 0 0 0
FDSize: 64
Groups: 0
NStgid: 4171
NSpid: 4171
NSpgid: 4171
NSsid: 4170
Kthread: 0
VmPeak: 2272 kB
VmSize: 2268 kB
VmLck: 0 kB
VmPin: 0 kB
VmHWM: 1336 kB
VmRSS: 1336 kB
RssAnon: 84 kB
RssFile: 1252 kB
RssShmem: 0 kB
VmData: 212 kB
VmStk: 132 kB
VmExe: 8 kB
VmLib: 1824 kB
VmPTE: 32 kB
VmSwap: 0 kB
CoreDumping: 0
THP_enabled: 0
untag_mask: 0xffffffffffffff
Threads: 1
SigQ: 1/29140
SigPnd: 0000000000000000
ShdPnd: 0000000000000000
SigBlk: 0000000000000000
SigIgn: 0000000000000000
SigCgt: 0000000000000000
CapInh: 0000000000000000
CapPrm: 000001ffffffffff
CapEff: 000001ffffffffff
CapBnd: 000001ffffffffff
CapAmb: 0000000000000000
NoNewPrivs: 0
Seccomp: 0
Seccomp_filters: 0
Speculation_Store_Bypass: vulnerable
SpeculationIndirectBranch: unknown
Cpus_allowed: f
Cpus_allowed_list: 0-3
Mems_allowed: 0003
Mems_allowed_list: 0-1
voluntary_ctxt_switches: 0
nonvoluntary_ctxt_switches: 879ㅤ
/proc/P_ID/stat 파일에서는 프로세스의 현재 실행 정보와 관련된 내용들을 확인해볼 수 있다. 다소 불친절하긴 하지만, 각 칸이 의미하는 바는 정해져있다. 예를 들어서 14번째, 15번째 칸의 의미는 utime (사용자모드에서 실행된 CPU 시간), stime (커널 모드에서 실행된 CPU 시간) 이다.
pi07@pi07:/proc/4171 $ cat stat
4171 (pa) R 4170 4171 4170 34821 4170 4194560 103 0 0 0 99918 0 0 0 10 -10 1 0 371180 2322432 313 18446744073709551615 1 1 0 0 0 0 0 0 0 0 0 0 17 2 0 0 0 0 0 0 0 0 0 0 0 0 0
// utime : 99918
// stime : 0나는
vruntime값을 보고싶었는데, 이 값은 리눅스 스케줄러가 관리하는 민감한 값이라서 직접 내가 확인할 수 없는 값이라고 한다. 까비쓰.
ㅤ
또, 프로세스의 VMA 정보를 보고싶다면 /proc/P_ID/maps 파일을 확인해보면 된다. 잠시 만들어본 테스트용 프로세스에서는 이렇게 꽤나 많은 (예상보다 너무나도 많은) VMA 목록을 가지고 있는 것을 볼 수 있었다.

ㅤ
이외에도 top 같은 명령어에서 전체 프로세스들의 현재 실행 정보 (현재 활성 상태 or 작업 관리자st)를 확인할 수 있다.


ㅤ
이 정보는 언제 까보는거냐
CPU 사용 패턴을 보기 위해서 쓸 수 있다.
- 위에서 확인한
utime,stime을 분석해서 프로세스 처리에 시간을 많이 사용하는지, 아니면 커널 호출로 시간을 많이 사용하는지를 분석할 수 있다. nonvoluntary_ctxt_switches값을 보면 Context-Switch가 얼마나 발생하는지를 볼 수 있다. 이 값이 너무 높다면 선점을 비정상적으로 많이 당하고 있다는 의미이기에 우선순위를 좀 높여서 최적화를 기대해볼 수 있다.nice값을 통해 처리 우선순위가 중요한 프로세스들의 처리 시간을 앞당길 수 있다.
ㅤ
메모리 누수 또한 이 정보로 확인해볼 수 있다.
- 프로그램을 개발하다가, 시간이 지나면서 물리적 메모리 사용량
VmRSS의 값이 자꾸 증가한다거나 최대 사용량VmHWM과의 차이가 크다면 의심해볼 수 있다. - 또 가상 메모리의 크기
VSZ는 엄청 큰데 실제 사용하는 메모리RSS가 작다면, 프로세스가 메모리를 할당만 하고 사용하지 않는다거나 Swap Out이 자주 발생하게됨을 의심해볼 수 있다.
ㅤ
프로세스의 메모리 배치 충돌이 의심된다면
proc/P_ID/maps파일을 보고 힙, 스택, 라이브러리 등의 영역 주소 배치를 확인하고 혹시 충돌이 있는지 체크하기
ㅤ
네트워크장치와 I/O 지연이 길어진다면
- 프로세스의 상태가
DState 인지 확인해보자. (Uninterruptable Sleep - 인터럽트가 불가능한 블락 상태) 이 상태가 길게 유지된다면 장치와의 I/O가 심각하게 지연되고 있다는 의미. HW 드라이버 등의 문제가 발생했을 수 있다.
ㅤ
프로세스 관련 명령어들
명령어들은 굳이 분석하지 말고, 검색해서 사용 목적만 파악해두자.
| 명령어 | 내용 (설명) | 사용 목적 (언제 활용할 수 있는지) |
|---|---|---|
ps |
현재 실행 중인 프로세스들의 스냅샷을 보여줍니다. | 시스템에서 현재 어떤 프로세스들이 실행 중인지, PID(프로세스 ID), CPU/메모리 사용량 등을 확인할 때. (ps -ef 또는 ps aux 옵션이 주로 사용됨) |
top |
실시간으로 시스템의 CPU, 메모리 사용량 및 가장 활발한 프로세스 목록을 보여줍니다. | 시스템 자원 사용 현황을 모니터링하고, CPU를 가장 많이 소모하는 프로세스를 찾을 때. (실시간 모니터링) |
kill |
지정된 PID를 가진 프로세스에게 시그널을 보냅니다. | 특정 프로세스를 종료하거나 제어할 때. (예: 정상 종료 kill PID, 강제 종료 kill -9 PID) |
killall |
지정된 프로세스 이름을 가진 모든 프로세스에 시그널을 보냅니다. | 이름이 같은 여러 프로세스를 한 번에 종료해야 할 때. (예: killall firefox) |
bg |
멈춰있는(Stopped) 작업을 백그라운드(Background)에서 계속 실행하도록 전환합니다. | 실수로 Ctrl+Z를 눌러 멈춘 작업을 뒤에서 다시 실행해야 할 때. |
fg |
백그라운드에서 실행 중인 작업을 포그라운드(Foreground)로 가져와서 터미널과 연결합니다. | 백그라운드에서 실행 중인 작업의 출력을 확인하거나 입력을 제공해야 할 때. |
jobs |
현재 터미널 세션에서 백그라운드나 멈춰있는 작업(Job) 목록을 보여줍니다. | 현재 세션에서 관리 중인 작업들의 상태와 작업 번호를 확인할 때. |
nohup |
터미널 세션이 종료되어도 프로세스가 계속 실행되도록 합니다. | 장시간 실행해야 하는 스크립트나 프로그램을 터미널을 닫고도 계속 작동시키고 싶을 때. |
'Embedded System > Embedded Linux' 카테고리의 다른 글
| [Embedded Linux] 프로세스간 통신 IPC - 파일 기반의 IPC (0) | 2025.11.29 |
|---|---|
| [Embedded Linux] Linux 시그널 (0) | 2025.11.29 |
| [Embedded Linux] 라즈베리파이의 부팅 (1) | 2025.11.25 |
| [Embedded Linux] Linux 커널 아키텍처 (1) | 2025.11.25 |
| [Embedded Linux] 시스템콜 함수가 호출되면 아래에선 무슨일이 일어나나 (0) | 2025.11.24 |